📝介绍
上篇文章Lambda常见场景用法中已经间接使用到了Stream操作,你可能当时会有些疑问,问什么会使用Stream流呢?它到底是用来干什么的呢?
Java 8 引入了全新的Stream API。这里的Stream和I/O流不同,它更像具有Iterable的集合类,但行为和集合类又有所不同。
Stream API引入的目的在于弥补Java函数式编程的缺陷。对于很多支持函数式编程的语言,map()、reduce()基本上都内置到语言的标准库中了,不过,Java 8的Stream API总体来讲仍然是非常完善和强大,足以用很少的代码完成许多复杂的功能。
体验Stream流
案例需求
按照下面的要求完成集合的创建和遍历
- 创建一个集合,存储多个字符串元素
- 把集合中所有以"张"开头的元素存储到一个新的集合
- 把"张"开头的集合中的长度为3的元素存储到一个新的集合
- 遍历上一步得到的集合
❌ 原始方式示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public class MyStream {
public static void main(String[] args) {
//集合的批量添加
ArrayList<String> list1 = new ArrayList<>(List.of("张三丰","张无忌","张翠山","王二麻子","张良","谢广坤"));
//list.add()
//遍历list1把以张开头的元素添加到list2中。
ArrayList<String> list2 = new ArrayList<>();
for (String s : list1) {
if(s.startsWith("张")){
list2.add(s);
}
}
//遍历list2集合,把其中长度为3的元素,再添加到list3中。
ArrayList<String> list3 = new ArrayList<>();
for (String s : list2) {
if(s.length() == 3){
list3.add(s);
}
}
for (String s : list3) {
System.out.println(s);
}
}
}
|
✅ 使用Stream流示例代码
1
2
3
4
5
6
7
8
9
10
11
|
public class StreamDemo {
public static void main(String[] args) {
//集合的批量添加
ArrayList<String> list1 = new ArrayList<>(List.of("张三丰","张无忌","张翠山","王二麻子","张良","谢广坤"));
//Stream流
list1.stream().filter(s->s.startsWith("张"))
.filter(s->s.length() == 3)
.forEach(s-> System.out.println(s));
}
}
|
Stream的好处
- 直接阅读代码的字面意思即可完美展示无关逻辑方式的语义:获取流,过滤姓张,过滤长度为3,逐一打印
- Stream流把真正的函数式编程风格引入到了Java中
- 代码简洁
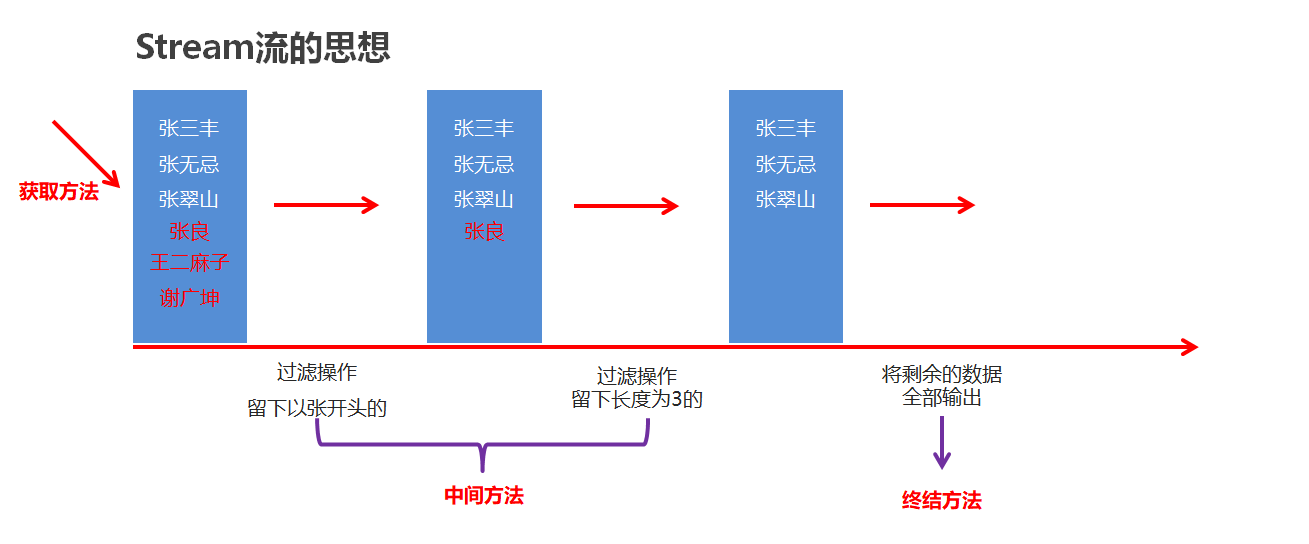
♠️Stream流的思想
 Stream流思想
Stream流思想
Stream流的三类方法
-
获取Stream流
-
中间方法
-
流水线上的操作
-
一次操作完成之后,还可以继续进行其他操作
-
终结方法
-
一个Stream流只能有一个终结方法
-
是流水线上的最后一个操作
♥️Stream流获取方式
| 获取方式 |
方法名 |
说明 |
| 单列集合 |
default Stream <E> stream |
Collection中的默认方法 |
| 双列集合 |
无 |
无法直接使用Stream |
| 数组 |
public static <T> Stream <T> stream(T[] array) |
Arrays工具类中的静态方法 |
| 零散数据 |
public static <T> Stream <T> of(T…values) |
Stream接口中的静态方法 |
-
Collection体系集合
使用默认方法stream()生成流
-
Map体系集合
把Map转成Set结合,间接的生成流
-
数组
通过Arrays中的静态方法strean生成流
代码演示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
public class StreamDemo {
public static void main(String[] args) {
//Collection体系的集合可以使用默认方法stream()生成流
List<String> list = new ArrayList<String>();
Stream<String> listStream = list.stream();
Set<String> set = new HashSet<String>();
Stream<String> setStream = set.stream();
//Map体系的集合间接的生成流
Map<String,Integer> map = new HashMap<String, Integer>();
Stream<String> keyStream = map.keySet().stream();
Stream<Integer> valueStream = map.values().stream();
Stream<Map.Entry<String, Integer>> entryStream = map.entrySet().stream();
//数组可以通过Arrays中的静态方法stream生成流
String[] strArray = {"hello","world","java"};
Stream<String> strArrayStream = Arrays.stream(strArray);
//同种数据类型的多个数据可以通过Stream接口的静态方法of(T... values)生成流
Stream<String> strArrayStream2 = Stream.of("hello", "world", "java");
Stream<Integer> intStream = Stream.of(10, 20, 30);
}
}
|
♦️Stream中间方法
中间操作的意思是,执行完此方法后,Stream流依然可以继续执行其他操作
| 方法名 |
说明 |
Stream <T> filter(Predicate predicate) |
用于对流中的数据进行过滤 |
Stream <T> limit(long maxSize) |
返回此流中的元素组成的流,截取前指定参数个数的数据 |
Stream <T> skip(long n) |
跳过指定参数个数的数据,返回由该流的剩余元素组成的流 |
static <T> Stream <T> concat(Stream a, Stream b) |
合并a和b两个流为一个流 |
Stream <T> distinct() |
返回由该流的不同元素(根据Object.equals(Object) )组成的流 |
🔮filter操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public class MyStream {
public static void main(String[] args) {
// Stream<T> filter(Predicate predicate):过滤
// Predicate接口中的方法 boolean test(T t):对给定的参数进行判断,返回一个布尔值
ArrayList<String> list = new ArrayList<>();
list.add("林青霞");
list.add("张曼玉");
list.add("王祖贤");
list.add("柳岩");
list.add("张敏");
list.add("张无忌");
//filter方法获取流中的 每一个数据.
//而test方法中的s,就依次表示流中的每一个数据.
//我们只要在test方法中对s进行判断就可以了.
//如果判断的结果为true,则当前的数据留下
//如果判断的结果为false,则当前数据就不要.
// list.stream().filter(
// new Predicate<String>() {
// @Override
// public boolean test(String s) {
// boolean result = s.startsWith("张");
// return result;
// }
// }
// ).forEach(s-> System.out.println(s));
//因为Predicate接口中只有一个抽象方法test
//所以我们可以使用lambda表达式来简化
// list.stream().filter(
// (String s)->{
// boolean result = s.startsWith("张");
// return result;
// }
// ).forEach(s-> System.out.println(s));
list.stream().filter(s ->s.startsWith("张")).forEach(s-> System.out.println(s));
}
}
|
🔮limit&skip操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
public class StreamDemo {
public static void main(String[] args) {
//创建一个集合,存储多个字符串元素
ArrayList<String> list = new ArrayList<String>();
list.add("林青霞");
list.add("张曼玉");
list.add("王祖贤");
list.add("柳岩");
list.add("张敏");
list.add("张无忌");
//需求1:取前3个数据在控制台输出
list.stream().limit(3).forEach(s-> System.out.println(s));
System.out.println("--------");
//需求2:跳过3个元素,把剩下的元素在控制台输出
list.stream().skip(3).forEach(s-> System.out.println(s));
System.out.println("--------");
//需求3:跳过2个元素,把剩下的元素中前2个在控制台输出
list.stream().skip(2).limit(2).forEach(s-> System.out.println(s));
}
}
|
🔮concat&distinct操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public class StreamDemo {
public static void main(String[] args) {
//创建一个集合,存储多个字符串元素
ArrayList<String> list = new ArrayList<String>();
list.add("林青霞");
list.add("张曼玉");
list.add("王祖贤");
list.add("柳岩");
list.add("张敏");
list.add("张无忌");
//需求1:取前4个数据组成一个流
Stream<String> s1 = list.stream().limit(4);
//需求2:跳过2个数据组成一个流
Stream<String> s2 = list.stream().skip(2);
//需求3:合并需求1和需求2得到的流,并把结果在控制台输出
// Stream.concat(s1,s2).forEach(s-> System.out.println(s));
//需求4:合并需求1和需求2得到的流,并把结果在控制台输出,要求字符串元素不能重复
Stream.concat(s1,s2).distinct().forEach(s-> System.out.println(s));
}
}
|
♣️Stream终结方法
终结操作的意思是,执行完此方法之后,Stream流将不能再执行其他操作
| 方法名 |
说明 |
| void forEach(Consumer action) |
对此流的每个元素执行操作 |
| long count() |
返回此流中的元素数 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
public class MyStream {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("林青霞");
list.add("张曼玉");
list.add("王祖贤");
list.add("柳岩");
list.add("张敏");
list.add("张无忌");
//method1(list);
// long count():返回此流中的元素数
long count = list.stream().count();
System.out.println(count);
}
private static void method1(ArrayList<String> list) {
// void forEach(Consumer action):对此流的每个元素执行操作
// Consumer接口中的方法void accept(T t):对给定的参数执行此操作
//在forEach方法的底层,会循环获取到流中的每一个数据.
//并循环调用accept方法,并把每一个数据传递给accept方法
//s就依次表示了流中的每一个数据.
//所以,我们只要在accept方法中,写上处理的业务逻辑就可以了.
list.stream().forEach(
new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
}
);
System.out.println("====================");
//lambda表达式的简化格式
//是因为Consumer接口中,只有一个accept方法
list.stream().forEach(
(String s)->{
System.out.println(s);
}
);
System.out.println("====================");
//lambda表达式还是可以进一步简化的.
list.stream().forEach(s->System.out.println(s));
}
}
|
🎯Stream流收集操作
对数据使用Stream流的方式操作完毕后,可以把流中的数据收集到集合中
| 方法名 |
说明 |
| R collect(Collector collector) |
把结果收集到集合中 |
public static <T> Collector toList() |
把元素收集到List集合中 |
public static <T> Collector toSet() |
把元素收集到Set集合中 |
| public static Collector toMap(Function keyMapper,Function valueMapper) |
把元素收集到Map集合中 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
// toList和toSet方法演示
public class MyStream {
public static void main(String[] args) {
ArrayList<Integer> list1 = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
list1.add(i);
}
list1.add(10);
list1.add(10);
list1.add(10);
list1.add(10);
list1.add(10);
//filter负责过滤数据的.
//collect负责收集数据.
//获取流中剩余的数据,但是他不负责创建容器,也不负责把数据添加到容器中.
//Collectors.toList() : 在底层会创建一个List集合.并把所有的数据添加到List集合中.
List<Integer> list = list1.stream().filter(number -> number % 2 == 0)
.collect(Collectors.toList());
System.out.println(list);
Set<Integer> set = list1.stream().filter(number -> number % 2 == 0)
.collect(Collectors.toSet());
System.out.println(set);
}
}
/**
Stream流的收集方法 toMap方法演示
创建一个ArrayList集合,并添加以下字符串。字符串中前面是姓名,后面是年龄
"zhangsan,23"
"lisi,24"
"wangwu,25"
保留年龄大于等于24岁的人,并将结果收集到Map集合中,姓名为键,年龄为值
*/
public class MyStream {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("zhangsan,23");
list.add("lisi,24");
list.add("wangwu,25");
Map<String, Integer> map = list.stream().filter(
s -> {
String[] split = s.split(",");
int age = Integer.parseInt(split[1]);
return age >= 24;
}
// collect方法只能获取到流中剩余的每一个数据.
//在底层不能创建容器,也不能把数据添加到容器当中
//Collectors.toMap 创建一个map集合并将数据添加到集合当中
// s 依次表示流中的每一个数据
//第一个lambda表达式就是如何获取到Map中的键
//第二个lambda表达式就是如何获取Map中的值
).collect(Collectors.toMap(
s -> s.split(",")[0],
s -> Integer.parseInt(s.split(",")[1]) ));
System.out.println(map);
}
}
|
🏆总结
在 Java 8 之前,我们通常是通过 for 循环或者 Iterator 迭代来重新排序合并数据,又或者通过重新定义 Collections.sorts 的 Comparator 方法来实现,这两种方式对于大数据量系统来说,效率并不是很理想。Stream 的聚合操作与数据库 SQL 的聚合操作 sorted、filter、map 等类似。可见用 Stream API 可以写出多么简洁的代码,用其他的模型也可以写出来,但是代码会非常复杂。